FAQs are a polarizing form of content. Some content professionals think polished FAQs can be awesome (even if many are far from being so.) Many other content professionals believe FAQs can never be awesome. Some publishers treat FAQs as another outlet to promote the publisher’s message. Critics view FAQs as unnecessary clutter — an admission that the design of the content is failing.
I want to try to separate the light from the heat. FAQs may seem like a dinosaur from the earliest days of online publishing, but they are morphing into something much more intelligent than many content designers realize. FAQs will likely be more important in the future, not less. But they won’t act like most FAQs used today.
The Stigma of FAQs
FAQs are so loathed that slogans about them now show up on swag. A Twitter poll revealed that a “frequently asked” request for a coffee/tea mug slogan was “No FAQs.” The mug was duly made, and is appearing on office desks.

Lisa Wright, a technical communicator who has written one of the most insightful critiques of FAQs, invokes a ghoulish specter: “Like zombies in a horror film, and with the same level of intellectual rigor, FAQs continue to pop up all over the web.” Be afraid: FAQs can trigger nightmares!
There are plenty of valid criticisms of FAQs, including many that get scant attention. But there are also plenty of criticisms of FAQs that seem subjective, and merely reinforce pre-existing attitudes about them. Dinging FAQs can be fun and can help you bond with new friends. Mocking FAQs during a rabble rousing conference presentation is a sure crowd pleaser, although the glib assertions in such talks are hard to fact-check and challenge. I’ve seen critiques of FAQs that say categorically that users don’t want FAQs, without providing any evidence that would allow us to evaluate how accurate, or generalizable, such a statement is. Even data about FAQs can be difficult to evaluate. Analytics may show FAQs are being viewed, while usability tests may show FAQs are frustrating to use. Evaluating the value of FAQs requires a deep understanding of both content relationships and user expectations.
To say that FAQs don’t “spark joy” would be an understatement. FAQs carry a stigma: their existence can seem to signal failure. Lots of people wish they weren’t necessary. Why do customers keep asking these same questions again and again? What’s the root cause triggering this irritation? FAQs may not be a sign that there are problems in the content. FAQs may be a sign that there are problems in the products that the content must explain. Many common customer service-related questions are about low-level bugs: frequent points of friction that users encounter that vendors decide are not serious enough to prioritize fixing. People may ask: why can’t they do something on their phone that they can do on their desktop? In an ideal world, users wouldn’t have to ask questions. Everything would work perfectly and no thinking would be necessary. We should never give up on that aspiration. But the messy reality is that vendors ship products with bugs and limitations. Users will always want to do something that was deemed an edge case or a low priority. The gap between what’s available and what’s expected results in a question.
FAQs have been around since the earliest days of the internet. They arose because they provided a simple way for publishers to address information that audiences were seeking. FAQs were the first feedback loop on websites, long before usability testing or A/B testing became common. Users indicated through emails or searches the questions they had, and publishers provided answers. FAQs aren’t the only way to reply to user questions. But credible, relevant FAQs can signal that the publisher listens to what information people want to know. Susan Farrell of the usability research consultancy Nielsen Norman Group has concluded that “FAQs Still Deliver Great Value.”
FAQs are simply a generic content type, much like a table or video can be a generic content type or format. Content professionals should resist the temptation to categorically dismiss FAQs as a bad or evil content type. Few would condemn all videos as evil, even if there are plenty of examples of bad videos. FAQs are surprising hard to do well. They have to deliver important information, highly anticipated by the user, in a concise and precise way.
For many web publishers, FAQs are a poorly managed content type. Why are FAQs poorly managed? FAQ pages often suffer from unclear ownership. FAQs are located on one of the few web pages in an organization that may be used by both marketing and customer support. That dual ownership can create a tension about the purpose of the FAQs: the kinds of questions presented, and the kinds of answers allowed. Without clear ownership and or a clearly defined purpose, FAQ pages can become a dumping ground for random information that different parties want to publish. When that happens, FAQs are no longer about answering common customer questions; they are about exposing organizational anxieties. FAQs can share the governance problems of another high profile web page: the home page.
FAQs can seem dishonest at times. Not all FAQs are really “frequently asked” questions, even if they appear in a short list on a FAQ page. True FAQs are based on real questions from real users. Potemkin FAQs are questions that the publisher decided they wanted to talk about, or wanted to spin in a flattering light. I’ve seen FAQs with a strong marketing focus, such as “How is your product different than company X’s product?” Even if buyers are wondering about that, they aren’t looking for an answer on the FAQ page. FAQs are meant to answer factual questions — not provide opinion and commentary. FAQs are not a sales channel. They are not a list of potential buyer objections. Answers should answer, not sell.
The purpose of FAQs is to prevent the user from having to dig through pages of content to get an answer to a straightforward question. But if the user has to go digging through a long list of FAQs to find the question in order to find the answer, then the benefit of the FAQ has been nullified.
In order to decide if FAQs are appropriate, a publisher should understand when and why customers have a question to begin with? What triggers the question, and when is it triggered?
FAQs respond to a user need for information. Either the information is new to the user, or it has been forgotten. Several common scenarios arise. If customers are familiar with other similar organizations and now are considering your organization, they may ask questions so they can make a comparison. For example, they may want to know what’s your organization’s policy about an issue that’s important to them. If customers are already familiar with your organization, they may have questions about changes that may have occurred. For example, annual changes in tax policies routinely generate many questions about how such changes affect specific situations.
Using FAQs especially makes sense when the web isn’t the primary channel of communicating with audiences. If people are already reading your web content, there is little point having them find the FAQs if the question can be answered on the pages people are already visiting. But many FAQ scenarios arise from non-web channel interactions. People have an issue with a product they’ve bought, and are driven to the website looking for the answer. The BBC’s audiences hear about something on radio or TV, and want follow up details, so they head to the website. Someone is planning to visit a retail store, but has a question about the validity of a competitor coupon. And sometimes people have general questions that aren’t related to a specific task. Questions don’t always arise in the context of a web task. Providing answers can sometimes be a precondition to starting a task.
Questions and Answers as a Content Form
Questions and answers are a fundamental way of structuring content. Q&As are one of the oldest forms of content, and they can be traced to ancient times when content was oral. The conversational nature of questions and answers aligns closely to the increasingly post-document character of online content.
Published content should have a purpose. Questions put a spotlight on the purpose of the content. What question(s) does the content answer? Does it answer the question well? Is the question important?
A question can be called many things. When I lived in Britain, I discovered people made enquiries (with an “e”), which to my American ears sounded rather formal. Living in India, I notice few people have questions, but many people have doubts. People with doubts generally aren’t skeptical; they just want answers. Computer geeks will speak about queries. All these terms can be synonyms, though they can evoke subtly different connotations about intention and purpose, depending on one’s background. Do they need a formal verdict about eligibility? Are they confused? Are they exploring?
No matter how carefully-crafted a publisher’s content is, audiences will still have questions. Publishers will need to provide answers to those questions — as they are articulated by audiences. Publishers can’t expect that audiences will stop asking questions. Publishers can’t even expect that everyone will read through all their carefully crafted content. Publishers would be presumptuous to assume that their content will answer every question audiences have, and that information sought will always be easy to find within the text. One of the ironies of the anti-FAQ attitude is that while it claims to be audience-centric, it actually is publisher-centric. FAQ-phobia at its worst becomes an attitude of “No Questions Allowed: we’ll decide what you need to know, and will tell you when we decide you need to know about it.” Like a stern school teacher, the publisher doesn’t permit any participation.
It’s helpful to compare the characteristics of FAQ with those of Q&As found in online forums. They are similar, except that both the questions and answers in FAQs tend to be more fixed, as one party chooses both the question and the answer. Q&As in forums tend to be more fluid. In an open Q&A, it can be more transparent who raised the question, and users themselves may supply the answer. Questions in a Q&A can sometimes be duplicated (a sure sign they are frequently asked) and sometimes questions mutate: people ask variants, or request an update based on new circumstances. Answers sometimes spawn new questions. Q&As in forums can be less efficient than FAQs at directly answering common questions, but they can be effective surfacing what issues concern audiences, and how they are thinking about these issues.
Questions themselves can be interesting. One can see some common questions, and think: that’s a good question! Hadn’t thought to ask that myself, but interested to know the answer. For example, I found these questions on the Nestlé India website:
- “Are the natural trans fats in dairy as harmful for the body as man-made trans fats?”
- “Are stir fries healthy?”
The very presence of these questions provides an indication of what customers must be chatting about online and in social media. Questions can be the voice of the customer, if the questions are genuine.
Any form of published questions and answers involves some kind of moderation. FAQs typically don’t offer an “Ask Me Anything” form of openness — the questions selected are chosen editorially. But many Q&A sites allow such openness. Quora, StackExchange, and other sites allow users to pose any question they want (consistent with their guidelines), and users vote on the value of both the question and the answers. The success of these sites indicates that the question-and-answer format does service a useful role.
In the case of FAQs, publishers must decide which questions are common enough to merit an answer. Who specifically are FAQs meant to address: everyone, or specific groups of individuals? And what kinds of questions are appropriate to answer with FAQs? These are editorial decisions, and they need to be supported with the right structure for the content. Many FAQ problems arise from either not making clear editorial decisions, or not having the right structure in place to support the editorial decisions made.
FAQs can sprawl if governance is lacking. Some publishers use FAQs to broadcast information about things they think audiences should know about, even if audiences aren’t asking about them often. They lack a process to evaluate the importance of a question to the audience.
Many people think about FAQs as a single destination page. But some publishers have multiple FAQ pages. When FAQs are treated as web pages, users may never even find the questions and answers. They need to figure out two things: whether their query is a frequently asked question, and knowing where the FAQs are located. Audiences ideally shouldn’t have to think about where the answers live.
The content marketing software firm HubSpot seems to have over 7000 FAQ pages, covering different branded audience and task-themed areas of their website, such as:
- Content Marketing Certification FAQ – HubSpot Academy
- HubSpot Developers FAQ
- Workflows | Frequently Asked Questions – HubSpot Academy
- Frequently Asked Questions – HubSpot Design
- HubSpot Partner Program FAQs
What a mess — how is the user supposed to know where to get an answer?
Such sprawl is common when marketing organizations dominate the process. Both questions and answers get framed by marketing segmentation. The supply of answers — the stuff to talk about — drives the process, instead of the supply of questions. That creates a risk that the FAQs don’t sound authentic. They can sound as if a blurb about something was written, and only then was a leading question created to become its heading. In Hubspot’s case, even the title of blog posts use the term FAQ. While it can be appropriate to address common questions in a blog post, those shouldn’t be labelled as FAQs.
Some frequently asked questions reflect customer skepticism. For example, MeWe, a social network site, claims to be free and to respect user privacy. They have a FAQ on how they can be free and make money. The question seems genuine, even if the answer seems vague.

Not only should the questions be important and relevant to many people, their answer needs to concise enough to cover the question’s scope. Open ended questions fail that test: short answers will fail to satisfy everyone’s criteria. Answers should not involve “it depends…” unless the answer provides onward links to explain different dimensions relating to the question. Overly general answers can sound evasive.
FAQs prove their value when they deliver brevity. Audiences don’t want to wade through lengthy text to find an answer. A classic case of a mismatch between questions and content are terms and conditions (T&Cs). While there may be legal reasons for having a long terms and conditions document, the information is hard to access. Apple’s terms and conditions would take nine hours to read completely. Users will have specific questions, and should be able to get specific answers without having to scan or read the T&Cs.
Publishers need to clearly convey what kind of questions are covered by FAQs. Many users will assume frequently asked questions are perennial questions repeatedly asked by people over time —a sort of greatest hits of factoids. But some publishers such as the BBC introduce the notion of “most popular” FAQs, which is confusing. Many users will assume that frequent questions are popular ones. But the BBC seems to describe lots of questions as FAQs, and then scores them by popularity, which can fluctuate. Popular questions may relate to how to get tickets to show or purchase a calendar linked to a program. Popular questions may be shorted lived and of interest only to a limited subgroup of visitors. There certainly needs to be a way to address questions that become suddenly and perhaps momentarily popular, but FAQ pages are customarily static. Many users won’t expect answers to such questions on a FAQ page.
Matching Questions with Answers: The issue of Intention
The root of question is “quest.” Users are on a quest. Questions arise because users need to understand something in order to do something. It is not always clear why someone is asking a question. Sometimes there could be more than one reason. Some people might ask about a return policy because they want to try the product before committing. Others ask because they are buying a gift and don’t know if the recipient will like it.
A core design challenge for FAQs is understanding how specific or general a user intention is. This gets into how to handle the granularity of questions and answers.
First, let’s break down the components of the customer-publisher interaction.
The quaeritur (the question asked) needs a corresponding quaesitum (a solution). While it sounds simple to match these two parts, in the word of online information the process is slightly more complex. It’s actually a three stage process:
- Question that was asked (the user query)
- The question that was answered (the published question or statement)
- The answer that was provided (or elaboration of the statement)
There are several places where the process could go wrong.
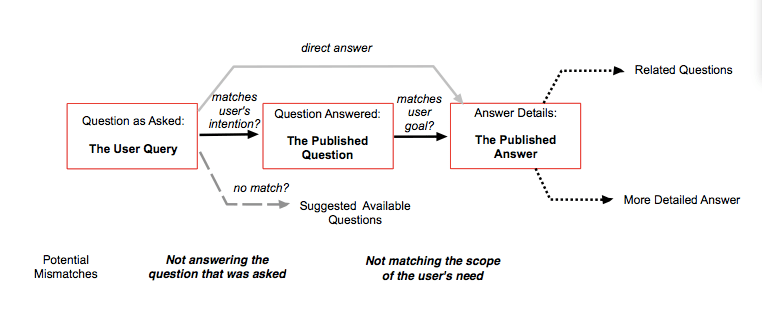
The user query may not match the published FAQ question. If the user sees a list of questions on a FAQ page, they may not see a question that matches how they are thinking about an issue. There are many reasons why the user query may not overlap with the published question. One reason is language: the terminology in a user query could be less formal and vaguer, and the user is unable to translate how they are thinking about the question into the publisher’s terminology. The other reason is a mismatch of scope. Users may be looking for more specific answers, and hence questions, than appear in a FAQ’s list of questions. Lisa Wright notes: “If a question appears to exclude the required information, the user may never click to see the answer, even if it is actually relevant.”
The published answer may not satisfy the user goal associated with their original query. The answer may be too general, or it may focus on details that while of interest to many, are not relevant to the specific user.
Because of the possibilities of mismatching, publishers need to remove extraneous steps and provide onward next steps to get users toward the answer they seek. If the user query matches an answer, it is best to show that answer directly, and not show how the publisher wrote the question, which could be broader. Specific queries are unlikely match published questions on a FAQ page. Users need the ability to express their own questions such as typing a search query, which can be mapped to appropriate answers. If the user query doesn’t match an available answer, it is best to show the nearest question for which there is an answer, assuming there is one.
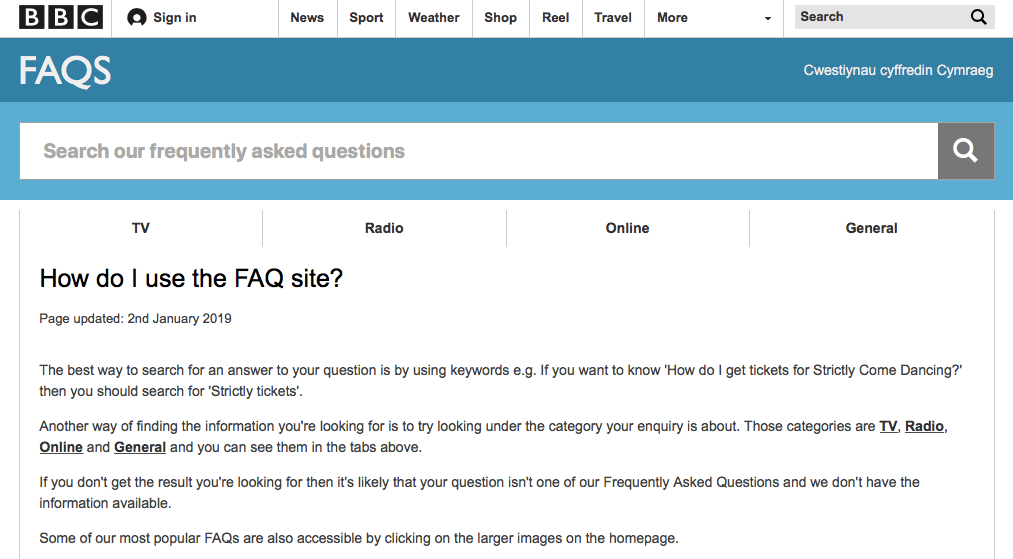
Users need to know: “What questions can I ask?” The BBC, which has a search interface to their FAQs, even has a FAQ on how to use their FAQ, a tacit admission that people aren’t sure what they can expect.
One of the major uncertainties associated with tell-me-what-you-want command-based queries is not knowing if one can ask a question. Voice interfaces are frustrating when the agent responds that they don’t understand the question, or when they misinterpret the question. Designers of query bots are developing ways to indicate query patterns a user can try that will yield useful answers.
The BBC’s FAQs reveal the problem of matching a user query to a publisher question. I have difficulty downloading BBC podcasts on my smartphone’s podcast app (rather than the BBC’s proprietary iPlayer app). But my query doesn’t really match the questions available, which are either more general or are irrelevant. My issue feels like it should be a frequently asked question. I’d be surprised if I’m alone in having problems accessing the BBC’s DRM-clamped, regionally-restricted audio content.

The BBC’s FAQ explains: “If you don’t get the result you’re looking for then it’s likely that your question isn’t one of our Frequently Asked Questions and we don’t have the information available.” But because I only see select questions that the BBC offers, I don’t really know if they failed to match my query with their questions (likely), or whether my query search their answers to find a match (possible). A user’s query might match the content of an available answer, but not the content of the question published that’s associated with that answer.
Most matching relies on matching specific trigger words, called hotwords in the case of voice interfaces. These trigger words are typically primitive. They don’t capture the context of the question, which can leads to a time-consuming process of clarification. Users ask: “How do I unclog my dishwasher?” And the answer could be another question (“Sounds like you need some help, tell me what model of dishwasher you have?”) Or the answer provided is too general to be useful (“Here are some tips on maintaining your dishwasher.”) As long as question-matching relies on trigger words, the interaction will be rudimentary. Over time, machines will become better interpreting questions. Major tech companies such as Amazon, Google, and Microsoft offer natural language processing APIs that publishers can access to help understand the meaning of the user query rather than just react to a keyword. Machines will understand the type of question, recognize synonyms, and connect relationships between different concepts mentioned.
From Preselected Questions to Permission-To-Ask
A major source of friction associated with FAQs are the limitations on presenting a list of questions to users. Listing more than one or two dozen questions results in sprawl. Long lists of questions are difficult to scan, because they lack contextual clues about what they refer to. People are looking for answers. They aren’t interested in looking for preselected questions. They aren’t looking for permission to ask a question.
But not all questions addressed need to appear in a list on a FAQ page. More and more, users expect to be able to ask questions directly, perhaps in a search query. Publishers need to be responsive to the actual questions that audiences want to ask. Publishers need to give audiences permission to ask. That involves not thinking about FAQs as existing only on a FAQ page.
Publishers need to embrace a “permission to ask” mindset. Part of giving users permission to ask is not making users have to visit your website to get an answer. A publisher can let them use Google, Facebook messenger, or Alexa to ask questions.
Publishers can’t assume they know all the questions that people will have that will be important. While user research is always necessary when prioritizing questions to answer, user research will never uncover all questions users will have. A widely quoted statistic is that 15% of all Google queries each day are new — they have never before been expressed. This has been true for many years. Not all high priority questions can be anticipated in advance. FAQs can provide a way for publishers to answer questions for which no published content has yet been created. FAQs can provide a brief answer that can subsequently elaborated upon in articles or other content. Even if user queries aren’t fully answered currently, publishers can provide a task flow that offers a next step for users to get the complete answer they need.
For FAQs to become more useful, they should be treated as a global resource. They are a body of answers, not just as a list of questions. They need to be unshackled from the FAQ page. Some developments in chat bot and voice bots suggests the overall direction for how answers must work across all channels. Answers don’t live in one place: they need to be everywhere.
Lisa Wright cautions that with FAQs “information can get out of sync quickly, resulting in duplicate or even contradictory content.” Most publishers manage FAQ is separately than other content. But it doesn’t need to be that way. The same question and answer can be inserted on relevant web pages as well as appearing on a FAQ page. If structured appropriately, there is only one instance of the content that is available multiple places.
The first task is to consider how questions need to be structured. Certain question structures indicate intents, for example:
- (Process) How do I….?
- (Checking rules) Can I…?
- (Options) Which…?
These intents can be characterized according to the purpose of the question and the purpose of the related information answering the question. The question needs to indicate what the user’s quest is about.
When questions have structure, they can better serve the needs of users. Many applications provide prompts to users about how to ask in a certain way [“Ask me….”]. Such prompts reduce the gap between matching the query with the question, and helping users understand the scope of addressable questions.
The second part of Q&A structuring is looking at the relationship between the question and answer.
- Can specific questions be answered with general answers?
- Can a specific query be an instance of a more general question?
For example, “Does Walmart accept international credit cards?” is a more specific question than “What forms of payment does Walmart accept?” The answer to the latter question may address the first question about international credit cards, but it will include many other details. “Does Walmart accept purchase orders?” might also lead to a comprehensive answer about forms of payment.
More specifically, questions and answers can involve three kinds of relationships:
- One Question, One Answer (a highly specific question-answer pair)
- One Question, Numerous Answers (many partial answers, or different opinions — that can be broken down into general and specific, or into follow up or related questions)
- Numerous Questions, One Answer (different specific questions have a single general answer)
In the cases where a question has numerous answers, the structuring may involve breaking down the answer. Users expect answers to be short. An answer overview could provide a link to other content that goes into more detail.
Finally, structuring questions and answers involves looking at the relationship between questions. Questions may not be independent. Other questions may be related, and useful for users to know about. Google, for example, provides related questions to user queries.

Improving Precision with Metadata
Even though FAQ pages may seem like dinosaurs, they are not going away. On the contrary: FAQ pages are in the process of being recognized as a distinct content type by the W3C’s schema.org community. Metadata is reinvigorating FAQs, and making them more useful and adaptable.
Increasingly, FAQs will be accessed outside of a website. Many users won’t go to a FAQ page to find the questions and read the answers. Metadata will allow them access to FAQs from their search page or using a chatbot or voice bot.
The utility of FAQs is limited when they lack metadata. It is hard to know what the question involves if it isn’t tagged according to the topic and intent of the question. It’s hard to associate related questions when such metadata doesn’t exist. And it’s hard to deal with more than a handful of questions, because the sprawl makes finding information difficult. Metadata can organize vast quantities of questions and answers behind the scenes, so that users only see relevant information, and can access it immediately.
Google relies on Q&A metadata to select answer snippets to display in search results. Google states: “marking up your Q&A page helps Google generate a better snippet for your page.” The user has a query, and metadata allows an answer without the user needing to go to a website.
As I discuss in my new book, No More Silos: Metadata Strategy for Online Publishing, metadata helps Quora keep track of the vast amount of questions and answers on its site. Quora is using Wikidata IDs — a metadata identifier that is derived from Wikipedia. These IDs can bring great precision to sometimes ambiguously worded questions.
Jay Myers of Best Buy, one the pioneers in the commercial applications of semantic metadata, explored in a recent blog post how one can model the relationship of topics that can be asked in a voice user interface such as Alexa. He shows how a class of products such as routers can have a range of common issues such as being slow or having connection problems. These issues are linked to tips to resolve issues. There’s huge potential for questions to become the gateway to all kinds of very specific information. This transition is just beginning.
Already, schema.org offers a extensive vocabulary for handling questions and answers. The vocabulary gives publishers the ability to structure questions and answers to meet different user needs.

First, the schema.org vocabulary offers different ways to indicate what a question is about. This goes beyond the simple tagging that exists in most content management systems. The publisher can indicate the primary topic that the question addresses. But the metadata can also provide more context about the question. It can indicate what other topics are mentioned in the question. And it also indicate whether the question is part of a broader question or series of questions, which can signal related questions. Finally, there’s a metadata property for keywords, which can be used for taxonomy terms that classify the purpose of the question, such as diagnosis or repair (the keywords can be tags and don’t have to be the literal words appearing in the question.) Publishers can also indicate the audience segment for the question, such as “existing owners” or “beginners.” These different properties can make the intention of the question much more precise, and transcend the limitations of matching specific words used in the question.
The schema.org vocabulary provides a range of options to indicate what’s included in an answer. As with the question, the answer can properties to indicate what an answer is about and mentions (an answer might mention something that’s not mentioned in the question.) These properties allow the publisher to deliver the answer when the user asks about a specific solution instead of asking more generally about options that are available. Another feature available is the ability to publish multiple answers. Publishers might publish provisional answers that users can vote on to determine if the answer is helpful or not. They can select an answer as being the best answer or accepted answer. Both Google and Bing already rely on these properties when presenting answers to certain questions that involve a range of perspectives. When providing an answer, publishers can indicate that they are the source of the information using the publisher property. This allows for attribution when users get an answer back when doing a search, or when asking a bot. The metadata allows the bot to say “According to Acme Corporation…” before presenting the answer.
Suppose users have questions that aren’t already answered? Schema.org metadata can cover that scenario as well. The metadata can capture the asking of a question. The user might fill out a form to ask a question, and might indicate the product they own if their question relates to that product. The organization then receives the question and can develop and publish an answer. When the answer is published, the user requesting the answer can be notified. The structure allowing all this to happen is available within the metadata standard.
Conclusions
The FAQ page is no longer the only place that questions and answers are accessed. The FAQ page could lose its role as a destination that users look for to get answers. Yet content in the form of questions and answers is poised to become more important, especially as conversational interfaces become more sophisticated and are used to access more kinds of information. FAQs will need to cover more questions and answers, not just the handful of Q&As shown on the FAQ page.
While FAQs have great potential to address user needs, FAQs will be frustrating for users if content designers treat questions and answers simply as text instead of as structure. Unless FAQs are structured appropriately, users will have trouble accessing relevant answers. FAQs need metadata to support the user’s quest for information. Metadata standards to describe Q&As already have a big influence on how readily audiences can discover the answers they are seeking.
— Michael Andrews
