For many years, the people designing, managing, and delivering user experiences have pursued the LEGO ideal – making experiences modular.
Content teams have aimed to make content modular so that it can be assembled in multiple ways. UI design teams have worked to make user interfaces modular so they can be assembled in different ways as well.
More recently, vendors have embraced the LEGO ideal. The IT research firm Gartner labeled this modular approach as “composable” and now scores of SaaS firms endorse composability as the most desirable approach for building user experiences.
The LEGO ideal has become a defining North Star for many digital teams.
The appeal of LEGO is easy to fathom. LEGO is familiar to almost everyone.
Though LEGO was not the first construction kit toy that allowed parts to be connected in multiple ways, it has by far been the most successful. LEGO is now the world’s largest toymaker.
But LEGO’s appeal stems from more than its popularity or the nostalgia of adults for pleasant childhood memories. LEGO teaches lessons about managing systems – though those lessons are often not well understood.
What LEGO figured out: Clutch Power
What’s been the secret to LEGO’s success? Why has LEGO, more than any other construction toy, achieved sustained global success for decades?
Many people attribute LEGO’s success to the properties of the bricks themselves. The magic comes from how the bricks fit together,
The Washington Post noted in 1983 the importance of “the grip that holds one piece to another. Measurements have to be exact down to minute fractions of an inch, which requires high-precision machinery and closely monitored quality control.”
The ability of the bricks to fit together so well has a name: clutch power.
The fan blog Brick Architect defines clutch power as “Newtons of force to attach or remove the part.”
The Washington Post noted that the bricks’ clutch power translated into “market clutch power”: how solidly the bricks built a grip with consumers.
Clutch power makes bricks more powerful:
Bricks can connect easily – they snap together
Bricks can be disassembled easily by pulling them apart
Bricks are not damaged or deformed through their repeated use
Bricks are infinitely reusable.
Clutch power is an apt metaphor for how brinks connect. Like the clutch in a car that shifts between gears, clutch power allows bricks of different sizes and roles to work together to deliver a bigger experience.
What makes content and design LEGO-like?
Truth be told, most content and design modules don’t snap together like LEGOs. Content and design modules rarely exhibit clutch power.
Even if the original intent was to create a LEGO-like kit of parts, the actual implementation doesn’t deliver a LEGO-like experience. It’s important to move past the pleasing metaphor of LEGOs and explore what makes LEGOs distinctive.
LEGO bricks aren’t for very small children – they are a choking hazard. Similarly, some teams figuratively “choke” when trying to manage many small content and design elements. They are overwhelmed because they aren’t mature enough to manage the details.
Attempts to create modularity in content and design often fall short of the LEGO ideal. They resemble LEGO’s junior sibling, DUPLO, offering simple connections of a limited range of shapes. In addition to generic bricks, DUPLO includes less general pieces such as specialized shapes and figures. It reduces the choking hazard but limits what can be built.
We find examples of DUPLO-like modularity in many UX processes. A small interaction pattern is reused, but it only addresses a very specific user journey such as a form flow. Small UI “molecules” are defined in design systems, but not more complex organisms. Help content gets structured, but not marketing or app content.
The limitation of DUPLO approach is the modularity isn’t flexible. Teams can’t create multiple experiences from the pieces.
When teams can’t create complex experiences out of small pieces, they resort to gluing the pieces together. Pieces of content and design get glued together – their connections are forced, preventing them from being reused easily. The outputs become one-off, single-use designs that can’t be used for multiple purposes.
Some people glue together LEGO bricks, even though doing so is not considered an approved best practice. They create an edifice that is too fragile and too precious to change. Their design is too brittle to take advantage of the intrinsic clutch power of the bricks. They create a single-use design. They use modularity to build a monolith.
Digital teams routinely build monolithic structures from smaller pieces. They create content templates or frontend design frameworks that look and behave a certain way but are difficult to change. They build an IKEA product that can’t be disassembled when you need to move.
So what gives content and design clutch power? What allows pieces to connect and be reconfigured?
The digital equivalent of clutch power is systems interface design – how the interfaces between various systems know of and can interact with each other. It determines whether the modules are created in a way that they are “API-first” so that other systems can use the pieces without having to interpret what’s available.
More concretely, giving content and design modules clutch power involves defining them with models. Models show how pieces can fit together.,
Models define things (resources) and their relationships, highlighting that things have a rich set of potential connections. They can snap together in many ways, not just in one way.
Defining things and their relationships is not easy, which is why the LEGO ideal remains elusive for many digital teams. It requires a combination of analytic and linguistic proficiency. Relationships are of two kinds:
Conceptual relationships that express the properties that things share with each other, which requires the ability to name and classify these properties clearly, at the right granularity (abstraction), to enable connection and comparison with appropriate precision.
Logical relationships that express the constraints and requirements of things and their values, which calls for the ability define what is normal, expected, exceptional, and prohibited from the perspective of multiple actors engaged in an open range of scenarios.
Modeling skills transcend the priorities of UI and content “design”, which focus on creating a product intended to support a single purpose. Modeling skills are more akin to engineering, without being cryptic. Modular pieces must be easy to connect, cognitively and procedurally.
We sometimes find organizations hire content engineers, content architects, information architects, or UI engineers, but most often designers and developers are in charge of implementation. We need more folks focused on creating clutch power.
What LEGO is still learning – and their lessons for digital teams
LEGO created a system that could grow. It expanded by offering new brick shapes that allow a wider range of items to be built.
LEGO has proved remarkably enduring. But that doesn’t mean it doesn’t need to adapt. To maintain market clutch power, LEGO needs to adapt to a changing market. Its past formulas for success can no longer be relied upon.
LEGO’s bricks are made from ABS plastic. ABS plastic gives the bricks their clutch power. But they are also environmentally bad as they are petroleum-based and have a big carbon footprint. As the world’s biggest toymaker, producing billions of plastic bricks, LEGO needs to change its model.
LEGO has tried to change the formula for their bricks. They’ve sought to replace ABS with recycled polyethylene terephthalate (RPET) but found it too soft to provide the needed clutch power. Additives to RPET, which would make it safer and more durable, require too much energy consumption. After intensive research, LEGO is discovering there’s no simple substitute for ABS.
LEGO’s dilemma highlights the importance of creating a system that can adapt to changing priorities. It’s not that clutch power became less important. But it had to fit in with new priorities of reducing carbon emissions.
One option LEGO is looking at is how to enable the “recircling” of bricks. How can bricks in one household, when no longer needed, be re-entered into the economy? LEGO is looking at a “circular business model” for bricks.
A circular model is one that digital teams should look at as well. The aim should not just be how a team can reuse their content and design modules, but also how other parts of their organization can reuse them, and perhaps, how outside parties can use them too. An API-first approach makes recirculation much easier. Better collaboration from vendors would also help.
Decoupled design architectures are becoming common as more organizations embrace headless approaches to content delivery. Yet many teams encounter issues when implementing a decoupled approach. What needs to happen to get them unstuck?
Digital experts have long advocated for separating or decoupling content from its presentation. This practice is becoming more prevalent with the adoption of headless CMSs, which decouple content from UI design.
Yet decoupling has been held back by UI design practices. Enterprise UX teams rely on design systems too much as the basis for organizing UIs, creating a labor-intensive process for connecting content with UI components.
Why decoupled design is hard
Decoupled design, where content and UI are defined independently, represents a radical break from incumbent practices used by design teams. Teams have been accustomed to defining UI designs first before worrying about the content. They create wireframes (or more recently, Figma files) that reflect the UI design, whether that’s a CMS webpage template or a mobile app interface. Only after that is the content developed.
Decoupled design is still unfamiliar to most enterprise UX teams. It requires UX teams to change their processes and learn new skills. It requires robust conceptual thinking, proactively focusing on the patterns of interactions rather than reactively responding to highly changeable details.
The good news: Decoupling content and design delivers numerous benefits. A decoupled design architecture brings teams flexibility that hasn’t been possible previously. Content and UI design teams can each focus on their tasks without generating bottlenecks arising from cross-dependencies. UI designs can change without requiring the content be rewritten. UI designers can understand what content needs to be presented in the UI before they start their designs. Decoupling reduces uncertainty and reduces the iteration cycles associated with content and UI design changes needing to adjust to each other.
It’s also getting easier to connect content to UI designs. I have previously argued that New tools, such as RealContent, can connect structured content in a headless CMS directly to a UI design in Figma. Because decoupled design is API-centric, UX teams have the flexibility to present content in almost any tool or framework they want.
The bad news: Decoupled design processes still require too much manual work. While they are not more labor intensive than existing practices, decoupled design still requires more effort than it should.
UI designers need to focus on translating content requirements into a UI design. The first need to look at the user story or job to be done and translate that into an interaction flow. Then, they need to consider how users will interact with content on screen by screen. They need to map the UI components presented in each screen to fields defined in the content model
When UX teams need to define these details, they are commonly starting from scratch. They map UI to the content model on a case-by-case basis, making the process slow and potentially inconsistent. That’s hugely inefficient and time-consuming.
Decoupled design hasn’t been able to realize its full potential because UX design processes need more robust ways of specifying UI structure.
UI design processes need greater maturity
Design systems are limited in their scope. In recent years, much of the energy in UI design processes has centered around developing design systems. Design systems have been important in standardizing UI design presentations across products. They have accelerated the implementation of UIs.
Design systems define specific UI components, allowing their reusability.
But it’s essential to recognize what design systems don’t do. They are just a collection of descriptions of the UI components that are available for designers to use if they decide to. I’ve previously argued that Design systems don’t work unless they talk to content models.
Design systems, to a large extent, are content-agnostic. They are a catalog of empty containers, such as cards or tiles, that could be filled with almost anything. They don’t know much about the meaning of the content their components present, and they aren’t very robust in defining how the UI works. They aren’t a model of the UI. They are a style guide.
Design systems define the UI components’ presentation, not the UI components’ role in supporting user tasks. They define the styling of UI components but don’t direct which component must be used. Most of these components are boxes constructed from CSS.
Unstructured design is a companion problem to unstructured content. Content models arose because unstructured content is difficult for people and machines to manage. The same problem arises with unstructured UI designs.
Many UI designers mistakenly believe that their design systems define the structure of the UI. In reality, they define only the structure of the presentation: which box is embedded in another box. While they sometimes contain descriptive annotations explaining when and how the component can be used, these descriptions are not formal rules that can be implemented in code.
Cascading Style Sheets do not specify the UI structure; it only specifies the layout structure. No matter how elaborately a UI component layout is organized in CSS or how many layers of inheritance design tokens contain, the CSS does not tell other systems what the component is about.
Designers have presumed that the Document Object Model in HTML structures the UI. Yet, the structure that’s defined by the DOM is rudimentary, based on concepts dating from the 1990s, and cannot distinguish or address a growing range of UI needs. The DOM is inadequate to define contemporary UI structure, which keeps adding new UI components and interaction affordances. Although the DOM enables the separation of content from its presentation (styling), the DOM mixes content elements with functional elements. It tries to be both a content model and a UI model but doesn’t fulfill either role satisfactorily.
Current UIs lack a well-defined structure. It’s incredible that after three decades of the World Wide Web, computers can’t really read what’s on a webpage. Bots can’t easily parse the page and know with confidence the role of each section. IT professionals who need to migrate legacy content created by people at different times in the same organization find that there’s often little consistency in how pages are constructed. Understanding the composition of pages requires manual interpretation and sleuthing.
Even Google has trouble understanding the parts of web pages. The problem is acute enough that a Google research team is exploring using machine vision to reverse engineer the intent of UI components. They note the limits of DOMs: “Previous UI models heavily rely on UI view hierarchies — i.e., the structure or metadata of a mobile UI screen like the Document Object Model for a webpage — that allow a model to directly acquire detailed information of UI objects on the screen (e.g., their types, text content and positions). This metadata has given previous models advantages over their vision-only counterparts. However, view hierarchies are not always accessible, and are often corrupted with missing object descriptions or misaligned structure information.”
The lack of UI structure interferes with the delivery of structured content. One popular attempt to implement a decoupled design architecture, the Blocks Protocol spearheaded by software designer Joel Spolsky, also notes the unreliability of current UI structures. “Existing web protocols do not define standardized interfaces between blocks [of content] and applications that might embed them.”
UI components should be machine-readable
Current UI designs aren’t machine-readable – they aren’t intelligible to systems that need to consume the code. Machines can’t understand the idiosyncratic terminology added to CSS classes.
Current UIs are coded for rendering by browsers. They are not well understood by other kinds of agents. The closest they’ve come is the addition of WAI-ARIA code that adds explicit role-based information to HTML tags to help accessibility agents interpret how to navigate contents without audio, visual, or haptic inputs and outputs. Accessibility code aims to provide parity in browser experiences rather than describe interactions that could be delivered outside of a browser context. Humans must still interpret the meaning of widgets and rely on browser-defined terminology to understand interaction affordances.
The failure of frontend frameworks to declare the intent of UI components is being noticed by many parties. UI needs a model that can specify the purpose of the UI component so that it can be connected to the semantic content model.
A UI model will define interaction semantics and rules for the functional capabilities in a user interface. A UI model needs to define rules relating to the functional purpose of various UI components and when they must be used. A UI model will provide a level of governance missing from current UI development processes, which rely on best-efforts adherence to design guidelines and don’t define UI components semantically.
When HTML5 was introduced, many UI designers hailed the arrival of “semantic HTML.” But HTML tags are not an adequate foundation for a UI model. HTML tags are limited to a small number of UI elements that are overly proscriptive and incomplete. HTML tags describe widgets like buttons rather than functions like submit or cancel. While historically, actions were triggered by buttons, that’s no longer true today. Users can invoke actions using many UI affordances. UI designers may change UI element supporting an action from a button to a link if they change the context where the action is presented, for example. Hard-coding the widget name to indicate its purpose is not a semantic approach to managing UIs. This issue becomes more problematic as designers must plan for multi-modal interaction across interfaces.
UI specifications must transcend the widget level. HTML tags and design system components fall short of being viable UI models because they specify UI instances rather than UI functions. A button is not the only way for a user to submit a request. Nor is a form the only way for a user to submit input.
When a designer needs to present a choice to users, the design system won’t specify which UI component to use. Rather it will describe a range of widgets, and it is up to the designer to figure out how they want to present the choice.
Should user choices be presented as a drop-down menu? A radio button? A slider? Design systems only provide descriptive guidance. The UI designer needs to read and interpret them. Rarely will the design system provide a rule based on content parameters, such as if the number of choices is greater than three, and the choice text is less than 12 characters, use a drop-down.
UIs should be API-ready. As content becomes more structured, semantically defined, and queriable via APIs, the content needs the UI designs that present it to be structured, too. Content queries need to be able to connect to UI objects that will present the content and allow interaction with the content. Right now, this is all done on an ad hoc basis by individual designers.
Let’s look at the content and UI sides from a structural perspective.
On the content side, a field may have a series of enumerated values: predefined values such as a controlled vocabulary, taxonomy terms, ordinal values, or numeric ranges. Those values are tracked and managed internally and are often connected to multiple systems that process information relating to the values.
On the UI side, users face a range of constrained choices. They must pick from among the presented values. The values might appear as a pick list (or a drop-down menu or a spinner). The first issue, noted by many folks, is the naming problem in design systems. Some systems talk about “toasts,” while other systems don’t refer to them. UI components that are essentially identical in their outward manifestations can operate under different names.
Why is this component used? The bigger structural problem is defining the functional purpose of the UI component. The component chosen may change, but its purpose will remain persistent. Currently, UI components are defined by their outward manifestation rather than their purpose. Buttons are defined generically as being primary or secondary – expressed in terms of the visual attention they draw – rather than the kind of actions the button invokes (confirm, cancel, etc.)
Constrained choice values can be presented in multiple ways, not just as a drop-down menu. It could be a slider (especially if values are ranked in some order) or even as free text where the user enters anything they wish and the system decides what is the closest match to enumerated values managed by the system.
A UI model could define the component as a constrained value option. The UI component could change as the number of values offered to users changed. In principle, the component updating could be done automatically, provided there were rules in place to govern which UI component to use under which circumstances.
The long march toward UI models
A design system specifies how to present a UI component: its colors, size, animation behaviors, and so on. A UI model, in contrast, will specify what UI component to present: the role of the component (what it allows users to do) and the tasks it supports.
Researchers and standards organizations have worked on developing UI models for the past two decades. Most of this work is little known today, eclipsed by the attention in UI design to CSS and Javscript frameworks.
In the pre-cloud era, at the start of the millennium, various groups looked at how to standardize descriptions of the WIMP (windows, icons, menu, pointers) interface that was then dominant. The first attempt was Mozilla’s XUL. A W3C group drafted a Model-Based User Interfaces specification (MBUI). Another coalition of IBM, Fujitsu, and others developed a more abstract approach to modeling interactions, the Software & Systems Process Engineering Meta-Model Specification.
Much of the momentum for creating UI models slowed down as UI shifted to the browser with the rise of cloud-based software. However, the need for platform-independent UI specification continues.
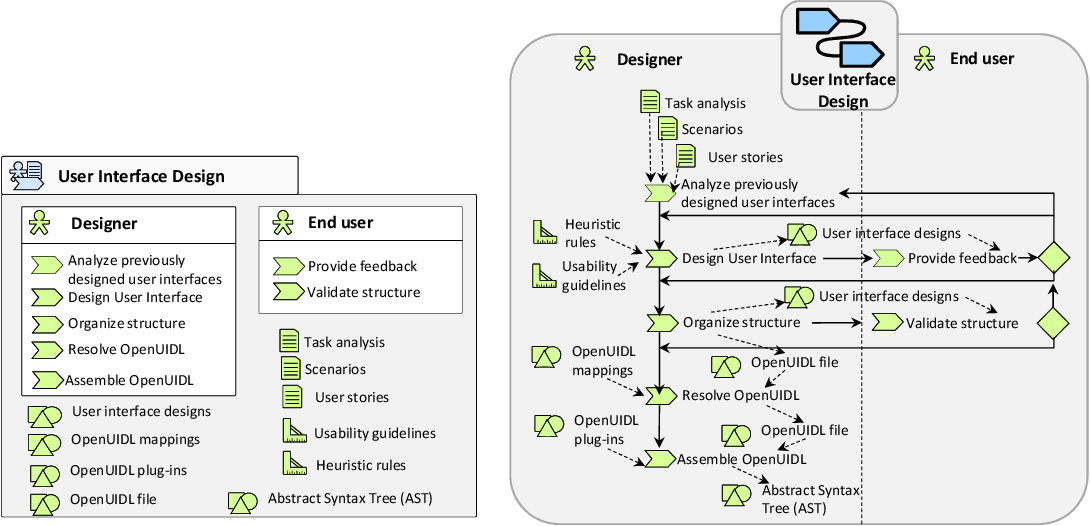
Over the past decade, several parties have pursued the development of a User Interface Description Language (UIDL). “A User Interface Description Language (UIDL) is a formal language used in Human-Computer Interaction (HCI) in order to describe a particular user interface independently of any implementation….meta-models cover different aspects: context of use (user, platform, environment), task, domain, abstract user interface, concrete user interface, usability (including accessibility), workflow, organization, evolution, program, transformation, and mapping.”
Another group defines UIDL as “a universal format that could describe all the possible scenarios for a given user interface.”
Task and scenario-driven UI modeling. Source: OpenUIDL
Planning beyond the web. The key motivation has been to define the user interface independently of its implementation. But even recent work at articulating a UIDL has largely been web-focused.
Providing a specification that is genuinely independent of implementation requires that it not be specific to any delivery channel. Most recently, a few initiatives have sought to define a UI model that is channel agnostic.
One group has developed OpenUIDL, “a user interface description language for describing omnichannel user interfaces with its semantics by a meta-model and its syntax based on JSON.”
UI models should work across platforms. Much as content models have allowed content to be delivered to many channels via APIs, UI models are needed to specific user interaction across various channels. While responsive design has helped allow a design to adapt to different devices that use browsers, a growing range of content is not browser-based. In addition to emerging channels such as mixed reality (XR) promoted by Apple and Meta and Generative AI chatbots promoted by Microsoft, Google, OpenAI, and others, the IoT revolution is creating more embedded UIs in devices of all kinds.
The need for cross-platform UI models isn’t only a future need. It shapes companies’ ability to coordinate decades-old technologies such as ATMs, IVRs, and web browsers.
A model can support a ‘portable UI.’ A prominent example of the need for portable UIs comes from the financial sector, which relies on diverse touchpoints to service customers. One recent UI model focused on the financial industry is called Omni-script. It provides “a basic technique that uses a JSON based user interface definition format, called omni-script, to separate the representation of banking services in different platforms/devices, so-called channels….the target platforms that the omnichannel services span over contains ATMs, Internet banking client, native mobile clients and IVR.”
The ideal UI model will be simple enough to implement but flexible enough to address many modes of interaction (including natural language interfaces) and UI components that will be used in various interfaces.
Abstraction enables modularity. UI models share a level of abstraction that is missing in production-focused UI specifications.
The process of abstraction starts with an inventory of UI components a firm has deployed across channels and touchpoints. Ask what system and user functionality each component supports. Unlike design systems development, which looks to standardize the presentation of components, UI models seek to formalize how to describe the role of each component in supporting a user or system task.
The abstraction of UI components according to the tasks they support. Source: W3C Model-Based UI XG
Suppose the functionality is intended to provide help for users. Help functionality can be further classified according to the kind of help offered. Will the functionality diagnose a problem, guide users in making a decision, disambiguate an instruction, introduce a new product feature, or provide an in-depth explanation of a topic?
A UI model maps relationships. Consider functionality that helps users disambiguate the meaning of content. We can refer to UI components as disambiguation elements in the UI model (a subset of help elements) whose purpose is to clarify the user’s understanding of terms, statements, assertions, or representations. They would be distinct from confirmation elements that are presented to affirm that the user has seen or heard information and acknowledges or agrees to it. The model would enumerate different UI elements that the UI design can implement to support disambiguation. Sometimes, the UI element will be specific to a field or data type. Some examples of disambiguation elements are:
Tooltips used in form instructions or labels
“Explain” prompt requests used in voice bots
Annotations used in text or images
Visual overlays used in photos, maps, or diagrams
Did-you-mean counter-suggestions used in text or voice search
See-also cross-references used in menus, indexes, and headings
The model can further connect the role of the UI element with:
When it could be needed (the user tasks such as content navigation, information retrieval, or providing information)
Where the elements could be used (context of application, such as a voice menu or a form.)
The model will show the M:N relationships between UI components, UI elements, UI roles and subroles, user tasks, and Interaction contexts. Providing this traceability will facilitate a rules-based mapping between structured content elements defined in the content model with cross-channel UX designs delivered via APIs. As these relationships become formalized, it will be possible to automate much of this mapping to enable adaptive UI designs across multiple touchpoints.
The model modularizes functionality based on interaction patterns. Designers can combine functional modules in various ways. They can provide hybrid combinations when functional modules are not mutually exclusive, as in the case of help. They can adapt and adjust them according to the user context: what information the user knows or has available, or what device they are using and how readily they can perform certain actions.
What UI models can deliver that’s missing today
A UI model allows designers to focus on the user rather than the design details of specific components, recognizing that multiple components could be used to support users, It can provide critical information before designers choose a specific UI component from the design system to implement for a particular channel.
Focus the model on user affordances, not widgets. When using a UI model, the designer can focus on what the user needs to know before deciding how users should receive that information. They can focus on the user’s task goals – what the user wants the computer to do for them – before deciding how users must interact with the computer to satisfy that need. As interaction paradigms move toward natural language interfaces and other non-GUI modalities, defining the interaction between users, systems, and content will be increasingly important. Content is already independent of a user interface, and interaction should become unbound to specific implementations as well. Users can accomplish their goals by interacting with systems on platforms that look and behave differently.
Both content and interactions need to adapt to the user context.
What the user needs to accomplish (the user story)
How the user can achieve this task (alternative actions that reflect the availability of resources such as user or system information and knowledge, device capabilities, and context constraints
The class of interaction objects that allow the user to convey and receive information relating to the task
Much of the impetus for developing UI models has been driven by the need to scale UI designs to address complex domains. For UI designs to scale, they must be able to adapt to different contexts.
UI models enable UX orchestration. A UI model can represent interactions at an abstract level so that content can be connected to the UI layer independently of which UI is implemented or how the UI is laid out.
For example, users may want to request a change, specify the details of a change, or confirm a change. All these actions will draw on the same information. But they could be done in any order and on various platforms using different modalities.
Users live in a multi-channel, multi-modal world. Even a simple action, such as confirming one’s identity while online, can be done through multiple pathways: SMS, automated phone call, biometric recognition, email, authenticator apps, etc.
When firms specify interactions according to their role and purpose, it becomes easier for systems to hand off and delegate responsibilities to different platforms and UIs that users will access. Currently, this orchestration of the user experience across touchpoints is a major challenge in enterprise UX. It is difficult to align channel-specific UI designs with the API layer that brokers the content, data, and system responses across devices.
UI models can make decoupled design processes work better
UI models can bring greater predictability and governance to UI implementations. Unlike design systems, UI models do not rely on not voluntary opt-in by individual developers. They become an essential part of the fabric of the digital delivery pipeline and remove inconsistent ways developers may decide to connect UI components to the content model – sometimes derisively referred to as “glue code.” Frontend developers still have options about which UI components to use, provided the UI component matches the role specified in the UI model.
UI governance is a growing challenge as new no-code tools allow business users to create their UIs without relying on developers. Non-professional designers could use components in ways not intended or even create new “rogue” containers. A UI model provides a layer to govern UIs so that the components are consistent with their intended purpose.
UI models can link interaction feedback with content. A UI model can provide a metadata layer for UIs. It can, for example, connect state-related information associated with UI components such as allowed, pending, or unavailable with content fields. This can reduce manual work mapping these states, making implementation more efficient,
An opportunity to streamline API management. API federation is currently complex to implement and difficult to understand. The ad hoc nature of many federations often means that there can be conflicting “sources of truth” for content, data, and transactional systems of record.
Many vendors are offering tools providing composable front-ends to connect with headless backends that supply content and data. However, composable frontends are still generally opinionated about implementation, offering a limited way to present UIs that don’t address all channels or scenarios. A UI model could support composable approaches more robustly, allowing design teams to implement almost any front end they wish without difficulty.
UI models can empower business end-users. Omnichannel previews are challenging, especially for non-technical users. By providing a rule-based encoding of how content is related to various presentation possibilities in different contexts and on various platforms, UI models can enable business users to preview different ways customers will experience content.
UI models can future-proof UX. User interfaces change all the time, especially as new conventions emerge. The decoupling of content and UI design makes redesign easier, but it is still challenging to adapt a UI design intended for one platform to present on another. When interactions are grounded in a UI model, this adaptation process becomes simpler.
The work ahead
While a few firms are developing UI models, and a growing number are seeing the need for them, the industry is far from having an implementation-ready model that any firm can adopt and use immediately. Much more work is needed.
One lesson of content models is that the need to connect systems via APIs drives the model-making process. It prompts a rethinking of incumbent practices and a willingness to experiment. While the scope of creating UI models may seem daunting, we have more AI tools to help us locate common interaction patterns and catalog how they are presented. It’s becoming easier to build models.